Implementation of a KPI Oriented Maintenance System
Parham Hosseini Yazdi
Researcher in Maintenance Management
Kerman, Iran
Email: parhamhosseini@gmail.com
1. Introduction
In recent years, many industrial organizations have moved toward implementing structured maintenance management systems to enhance equipment reliability and reduce production downtime. However, practical experience across several industries shows that, during the early stages of implementation, managers and specialists often encounter a wide range of concepts, indicators, guidelines, and operational procedures. Without a clear strategy, this complexity may lead to unnecessary complications and ultimately reduce the effectiveness of the maintenance system.
In such circumstances, focusing on numerous indicators simultaneously—without establishing a strategic priority—can result in resource dispersion, managerial uncertainty, and even a regression to conventional maintenance practices. This challenge is particularly evident in industries that lack a strong, systematic foundation in maintenance management.
With this context in mind, the present paper is built on the assumption that establishing a strategic focus on a single key indicator can facilitate both the implementation and continuous improvement of a maintenance system. In this regard, Mean Time Between Failures (MTBF), as an operationally measurable metric, can play a central role in guiding improvement initiatives. The aim of this study is to elaborate on this approach and to analyze how prioritizing MTBF influences other maintenance performance indicators.
Recent research emphasizes that maintenance performance should be assessed within a multidimensional, sustainability oriented framework. Saihi, Ben Daya, and As’ad (2022) identified and validated 63 sustainable maintenance performance indicators, demonstrating that maintenance metrics must be evaluated across environmental, social, and economic dimensions. These findings underscore the importance of focusing on key, influential indicators to improve the overall performance of maintenance units.
1.1 Objective of the Article
This article aims to investigate the most significant factors influencing maintenance management, evaluate their priority in organizations that lack a structured maintenance system, and propose a set of practical actions to improve equipment performance.
2. Theoretical Foundations and Key Indicators in Maintenance Management
In maintenance management systems, key performance indicators (KPIs) are recognized as essential tools for evaluating the effectiveness and efficiency of maintenance activities. Among the various indicators, metrics such as Mean Time Between Failures (MTBF), Mean Time To Repair (MTTR), and Overall Equipment Effectiveness (OEE) are widely recognized as fundamental and commonly used measures across different industries.
These metrics not only provide the basis for monitoring the performance of maintenance systems, but are also widely used in management dashboards and play an important role in decision making related to improving equipment reliability (IJEME, 2023).
2.1 Basic Failure and Repair Indicators (MTBF and MTTR)
In evaluating maintenance system performance, two fundamental indicators play a central role: Mean Time Between Failures (MTBF) and Mean Time To Repair (MTTR). These indicators serve as the foundation for calculating more advanced metrics, including reliability and availability.
MTBF
MTBF refers to the average duration of failure free operation of equipment between two successive failures. It
is typically calculated as:
\[
MTBF = \frac{\text{Total Operating Time}}{\text{Number of Failures}}
\]
An increase in MTBF reflects a lower failure rate and an improvement in the technical condition of the equipment. Consequently, MTBF is recognized as one of the most important measures of equipment reliability.
MTTR
MTTR represents the average time required to repair equipment and restore it to an operational state following a
failure. It is calculated as:
\[
MTTR = \frac{\text{Total Downtime}}{\text{Number of Failures}}
\]
A reduction in MTTR indicates improved maintainability, higher efficiency of the maintenance team, and greater effectiveness of maintenance processes.
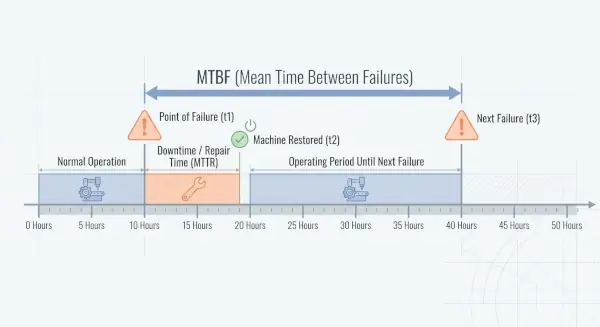
To clarify the relationship between these two indicators, the figure below illustrates a typical failure cycle. The time between two failures corresponds to MTBF, while the time required to restore the equipment to operation corresponds to MTTR. This cycle consists of two main components: the failure free operating period and the repair related downtime. Together, these components form the analytical basis for reliability and availability assessments.
In summary, MTBF reflects the interval between failures, whereas MTTR reflects the recovery time after failure. These indicators constitute the primary quantitative metrics used in this study to assess maintenance system performance. Practical analyses also show that continuous monitoring of MTBF and MTTR plays a crucial role in evaluating maintenance effectiveness and preventing productivity decline (Aji & Uchendu, 2025).
2.2 Reliability
Reliability is one of the most important indicators used to evaluate equipment performance in industrial systems. It refers to the probability that a component or system will perform its intended function without failure under specified operating conditions for a given period of time. Mathematically, reliability is defined as:
\[ R(t) = P(T > t) \]
where T denotes the time to failure of the equipment and t represents the specified operating duration. In many industrial applications, assuming a constant failure rate (i.e., an exponential distribution), the reliability function becomes:
\[ R(t) = e^{-\lambda t} \]
where λ is the failure rate. Considering the relationship:
\[ \lambda = \frac{1}{MTBF} \]
the reliability function can be rewritten as:
\[ R(t) = e^{-\frac{t}{MTBF}} \]
This relationship clearly shows that reliability is directly determined by MTBF: the greater the MTBF, the higher the value of R(t) for any specified operating time.
Analysis of the Reliability Curves
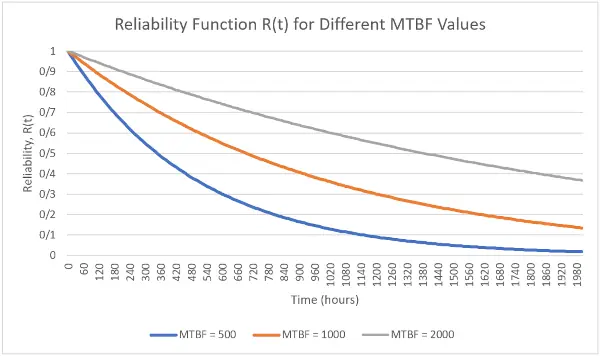
The figure illustrates the reliability curves for three MTBF values—500, 1000, and 2000 hours—over a 2000 hour interval. All three curves follow an exponential decay pattern; as time increases, the probability of remaining failure free gradually decreases. However, the rate of decline varies with the MTBF value.
For MTBF = 500 hours (blue curve), reliability decreases more rapidly, meaning the equipment reaches lower reliability levels sooner. In contrast, for MTBF = 2000 hours (gray curve), reliability declines much more slowly, allowing the equipment to maintain higher R(t) values over a longer period. The curve associated with MTBF = 1000 hours (orange curve) lies between these two cases.
This difference directly reflects the exponential relationship:
\[ R(t) = e^{-\frac{t}{MTBF}} \]
Thus, a higher MTBF results in:
• a slower decrease in the reliability curve,
• a higher probability of failure free operation over any time interval,
• and reduced unplanned production stoppages.
Managerial Implications
From a managerial standpoint, these results demonstrate that improving MTBF is not only a technical target but also a strategic lever for enhancing reliability and increasing overall equipment availability. Systematic efforts to improve MTBF—such as conducting root cause failure analysis, implementing preventive maintenance, and optimizing operating conditions—can significantly strengthen maintenance performance and production continuity.
Using real operational data, this study analyzes the relationship among MTBF, failure rate, and reliability, and confirms that reducing the failure rate and increasing MTBF lead to higher reliability values R(t) (Aji & Uchendu, 2025).
2.3 Availability
Availability is a key indicator used to evaluate equipment performance within maintenance systems. It represents the proportion of the total planned time during which equipment is in an operational state and ready for use. In other words, availability shows the fraction of scheduled time in which equipment is functioning without downtime and capable of performing its intended task.
Equipment availability is fundamentally determined by two factors: reliability and maintainability. Reliability expresses the probability that equipment will operate without failure over a given period, whereas maintainability reflects how quickly and efficiently the equipment can be restored to service after a failure.
In many maintenance engineering references, the inherent availability of equipment is expressed as:
\[ A = \frac{MTBF}{MTBF + MTTR} \]
where MTBF is the mean time between consecutive failures, and MTTR is the average time required to repair the equipment and return it to operational condition. According to this relationship, increasing MTBF (i.e., extending the failure free operating period) or decreasing MTTR (i.e., shortening the repair duration) directly leads to higher availability.
From a managerial standpoint, this equation highlights two primary pathways for improving maintenance system performance: reducing failure frequency and accelerating equipment recovery. Among these, initiatives that increase MTBF are particularly impactful, as they contribute to sustainable improvements in equipment availability and significantly reduce unplanned production downtime.
2.4 Maintenance and Operating Costs
Maintenance and repair costs can generally be classified into two major categories: direct costs and indirect costs.
• Direct costs
These include expenditures related to maintenance labor, the procurement and consumption of spare parts, the use of specialized tools and equipment, contractor services, and the execution of preventive and corrective maintenance activities.
• Indirect costs
Indirect costs are often not explicitly reflected in financial statements, yet they exert a substantial influence on an organization’s economic performance. Examples include the costs associated with production downtime, reduced production capacity, increased scrap or rework, declining product quality, delivery delays, and diminished customer satisfaction.
In modern physical asset management, the objective extends beyond simply reducing direct maintenance expenses. Instead, the focus is on optimizing the total life cycle cost (LCC) of the asset. Within this framework, decisions regarding maintenance strategies, spare parts inventory levels, and the type and timing of technical interventions should be made so as to minimize the combined direct and indirect costs over the equipment’s useful life.
From this perspective, indicators such as MTBF and MTTR are not merely technical performance parameters; they also shape the organization’s cost structure. Increasing MTBF reduces failure frequency, while reducing MTTR shortens downtime. Both improvements can significantly lower the indirect costs associated with production interruptions and enhance overall equipment productivity.
2.5 Maintenance Planning and Scheduling
Maintenance planning and scheduling represent essential components of effective physical asset management in industrial environments. The primary objective of this process is to organize and execute maintenance activities in a manner that preserves equipment reliability while minimizing disruptions to production operations. Within this framework, maintenance programs typically incorporate activities such as Preventive Maintenance (PM), Predictive Maintenance (PdM), and Overhaul interventions, each aimed at reducing failure probability and enhancing equipment performance.
Successful implementation of these programs requires close coordination among several organizational units, including maintenance, production, production planning, and spare parts inventory management. Insufficient coordination across these units can lead to delays in maintenance execution, shortages of spare parts, extended equipment downtime, and an overall decline in operational efficiency.
From a managerial perspective, effective planning and scheduling of maintenance activities play a critical role in improving performance indicators such as MTBF. By ensuring timely interventions, minimizing unexpected failures, and optimizing equipment operating conditions, a well structured maintenance planning system can significantly enhance overall system reliability and operational continuity.
2.6 Human Resources, Training, and Maintenance Culture
Human factors play a pivotal role in the effectiveness of any maintenance system. The skills, experience, and training levels of maintenance and operational personnel are critical for the timely detection of failure symptoms, the proper execution of maintenance tasks, and the prevention of recurrent failures. Well trained staff are able to identify problems more quickly and execute maintenance procedures more accurately, thereby reducing repair times and improving the MTTR indicator.
It is often assumed that employees receive the necessary basic training prior to the implementation of a structured maintenance system. However, practical experience demonstrates that training cannot be treated as a one time event; rather, it must be embedded as a continuous, on the job development process. In this context, the systematic use of feedback from system implementation, the analysis of performance results, and the review of occurred failures together with their corrective actions should be regarded as integral elements of an ongoing training program. This continuous feedback and learning cycle gradually enhances employees’ technical competence and decision making capabilities in maintenance management.
Beyond the technical dimension of training, cultivating an appropriate maintenance culture within the organization is of particular importance. In organizations where a preventive maintenance culture is effectively institutionalized, both production and maintenance personnel perceive themselves as jointly responsible for the operating condition of equipment. They are more attentive to early warning signs of failure and actively engage in the recording, reporting, and analysis of failure events. Such a culture reduces the frequency of unexpected failures, improves equipment reliability, and ultimately contributes to enhanced performance indicators, including MTBF.
2.7 Spare Parts and Inventory Management
Effective spare parts and inventory management represents a critical supporting element in the performance of maintenance systems. In many industrial settings, the unavailability of even a minor component can result in extended equipment downtime and significant production losses. Consequently, the systematic identification of critical spare parts is essential for ensuring operational continuity.
A structured inventory management approach should incorporate the analysis of historical consumption data, the classification of parts based on criticality, and the consideration of procurement lead times. These factors enable organizations to determine appropriate stock levels and reorder policies, thereby minimizing the risk of stockouts while avoiding excessive capital tied up in inventory.
From a performance perspective, optimized spare parts management directly contributes to reducing downtime duration and improving system availability. By ensuring timely access to required components, organizations can shorten repair times, enhance maintenance responsiveness, and ultimately improve key performance indicators such as MTTR and overall equipment effectiveness.
2.8 Maintenance Information Systems (CMMS)
Computerized Maintenance Management Systems (CMMS) are widely recognized as essential tools for managing maintenance related data. These systems typically provide functionalities such as work order management, failure recording, downtime tracking, spare parts control, and the generation of maintenance performance indicators. In organizations with mature maintenance practices, CMMS can significantly support data analysis and managerial decision making.
However, practical experience in many industrial environments indicates that during the early stages of maintenance system implementation—when information requirements are not yet clearly defined and process structures have not reached sufficient stability—the adoption of complex and costly CMMS solutions does not necessarily result in improved performance. In such contexts, excessive reliance on sophisticated software may increase operational complexity, create user resistance, and compromise data accuracy and consistency.
In the initial phases, simpler tools—such as structured databases or spreadsheet based systems (e.g., Excel)—may prove more effective for recording failures, tracking downtime, and conducting preliminary analyses. This approach facilitates a clearer understanding of equipment behavior and failure patterns while supporting the gradual development of standardized maintenance processes.
Once a coherent maintenance framework has been established and organizational information needs have been clearly articulated, the implementation of a comprehensive CMMS can be considered a logical next step in system maturation. Ultimately, the effectiveness of any maintenance information system depends not merely on data collection, but on the organization’s ability to transform recorded data into actionable insights that enhance performance indicators such as MTBF and overall system reliability.
3. Selection of a Core Indicator in Organizations Without a Structured Maintenance System
In many industrial organizations where a structured maintenance system has not yet been fully developed, operational conditions are typically characterized by run to failure practices, the absence of preventive maintenance programs, a lack of reliable equipment performance records, and a predominance of emergency repairs. In such environments, efforts to improve all maintenance performance indicators simultaneously are often limited by resource constraints, insufficient data availability, and the inherent complexity of implementing systemic improvements.
Under these circumstances, selecting a single core indicator to anchor the improvement process can provide a practical and manageable starting point. Focusing on one key metric enables organizations to direct their limited resources toward addressing the most critical performance gaps, establish a clear baseline for monitoring progress, and gradually build the foundational capabilities required for more advanced maintenance performance measurement in the future.
3.1 Proposed Parameter: Mean Time Between Failures (MTBF)
Among the various maintenance performance indicators, Mean Time Between Failures (MTBF) can serve as an effective starting point for improving maintenance performance in organizations lacking a structured system. MTBF is directly associated with failure frequency and, unlike many other indicators, can typically be measured using basic operational data, even in environments where comprehensive historical records are not available.
In practical terms, focusing on increasing MTBF entails reducing the number of failures, enhancing operating conditions, implementing preventive measures, and conducting systematic root cause analyses. Many of the actions taken to improve MTBF inherently contribute to broader maintenance performance improvements, even when other indicators are not explicitly monitored.
For example:
• Reducing failure frequency lowers equipment downtime and increases overall availability;
• Documenting and analyzing failures can streamline repair processes and consequently reduce MTTR;
• Minimizing failure events directly decreases maintenance expenditures and mitigates production losses associated with unscheduled interruptions.
Therefore, a strategic focus on MTBF provides a practical, measurable, and resource efficient entry point for performance improvement. It allows organizations with limited data, fragmented maintenance practices, or predominantly reactive maintenance regimes to initiate a structured improvement path while progressively developing the capabilities required for more advanced maintenance performance measurement and optimization.
4. Practical Actions to Increase MTBF and Their System Wide Effects on Maintenance Performance
In industrial environments characterized by limited resources, insufficient historical maintenance data, and a predominance of corrective or emergency repairs, directly targeting improvements in Mean Time Between Failures (MTBF) can provide one of the most practical and effective entry points for enhancing maintenance performance.
Increasing MTBF not only reduces the frequency of equipment failures but also generates broader positive effects across the maintenance system. In practice, many of the actions that contribute to extending the time between failures—such as improving operating conditions, implementing preventive measures, and analyzing failure causes—simultaneously lead to improvements in other key maintenance indicators. These improvements typically include shorter repair times (MTTR), higher equipment availability, and lower maintenance and production interruption costs.
This occurs because efforts aimed at reducing failure frequency often require organizations to identify underlying technical, operational, and managerial weaknesses within the maintenance system. Addressing these issues naturally promotes broader organizational learning, better maintenance practices, and more structured decision making processes.
The following sections outline the most important practical actions commonly implemented in industrial environments to increase MTBF and, consequently, improve overall maintenance system performance.
4.1 Identifying Failure Patterns and Recording Minimal Data
The first and most fundamental step toward improving MTBF is establishing a consistent and simple method for recording failure related information—even if this is done using a basic spreadsheet. In many industrial settings, sophisticated maintenance information systems are unavailable; however, meaningful insights can still be generated through minimal yet structured data collection.
When maintenance teams begin systematically documenting which failures occurred, on which equipment, when they happened, and why, several important improvements naturally emerge:
• Failure patterns become detectable, enabling the identification of recurring issues;
• Frequent or high impact problems are revealed, allowing maintenance efforts to be prioritized more effectively;
• Root cause analysis becomes feasible, as the collected information provides initial clues about underlying failure mechanisms;
• Failure and repair durations become measurable, creating the foundation for quantitative performance assessment.
Result:
Even with basic data recording, organizations gain the ability to calculate MTBF and MTTR for the first time. This initial measurement capability provides the baseline necessary to initiate structured performance improvement and supports the transition toward more proactive and data driven maintenance practices.
4.2 Root Cause Analysis of Failures and Eliminating the Most Frequent Causes
When increasing MTBF becomes a primary organizational objective, maintenance teams are naturally guided toward conducting failure analyses as part of their routine activities. Importantly, this analysis does not need to be complex or time consuming; even a brief, structured review can provide valuable insights.
A simple root cause analysis typically revolves around a few fundamental questions:
• Why did the failure occur?
• What technical or operational factors caused it?
• What actions can prevent its recurrence?
Despite its simplicity, this process enables organizations to distinguish between sporadic failures and those driven by consistent, underlying causes. Once the most frequent or high impact causes are identified—often representing a small subset of all observed failures in accordance with the Pareto principle—targeted corrective actions can be implemented.
Result:
Eliminating a limited number of dominant failure causes leads to a disproportionally large improvement in MTBF. This focused approach allows organizations with constrained resources to achieve substantial performance gains quickly, while simultaneously establishing the analytical habits necessary for more advanced reliability improvement initiatives.
4.3 Standardization of Repair Practices (Even When Standardization Is Not the Initial Objective)
Industrial experience demonstrates that once an organization begins focusing on failure reduction, maintenance teams soon recognize that non standardized repair practices are themselves a significant source of recurrent failures. Variability in repair methods, tools, or adjustment parameters often leads to inconsistent equipment performance and premature failures after intervention.
Thus, in pursuit of higher MTBF, organizations inevitably move toward establishing standardized repair procedures. Key actions typically include:
• Defining and documenting repair procedures to ensure repeatability and clarity;
• Establishing a uniform sequence of repair steps that minimizes omissions or incorrect order of operations;
• Standardizing technical parameters such as torque values, fixtures, tolerances, and alignment settings;
• Implementing post repair inspection checklists to verify the completeness and correctness of maintenance work.
Although such standardization may not have been the original goal, it often emerges as one of the most effective mechanisms for reducing recurring failures and stabilizing equipment reliability.
Side Effect:
As repair procedures become more consistent and structured, the average repair time (MTTR) tends to decrease as well. Standardization not only improves the reliability of outcomes but also enhances the efficiency and predictability of maintenance operations.
4.4 Improving Spare Parts Quality and Vendor Management (An Automatically Triggered Effect)
When an organization begins focusing on increasing MTBF, one of the earliest insights that emerges is the role of spare parts quality in driving failure frequency. As failures are tracked and analyzed, maintenance teams can quickly identify:
• Which components fail most frequently;
• Which parts exhibit inherently low quality or inconsistent performance;
• Which suppliers are associated with recurrent or premature failures.
These observations naturally lead to a more structured evaluation of spare parts and suppliers. As a result, organizations tend to:
• Review and revise their approved vendor list, removing suppliers associated with low quality or failure prone components;
• Source high risk parts from more reliable and higher quality vendors, ensuring consistency in equipment performance;
• Cleanse the inventory by replacing substandard or defective parts with components that meet appropriate technical specifications.
Result:
Through the systematic improvement of spare parts quality and supplier performance, organizations typically experience notable gains in MTBF, enhanced equipment reliability, and reduced unplanned production downtime. These improvements emerge almost automatically from the process of analyzing failure patterns, without requiring separate or complex initiatives.
4.5 Improving Operating Conditions
A substantial proportion of equipment failures can be attributed not to inherent design weaknesses, but to inadequate or suboptimal operating conditions. Common contributing factors include:
• Equipment overloading;
• Contamination (dust, moisture, or foreign particles);
• Elevated operating temperatures;
• Excessive vibration or misalignment;
• Deviation from standard operating procedures by operators.
When increasing MTBF becomes a central objective, organizations are compelled to examine these operational factors more systematically. This focus typically leads to:
• Reviewing and updating operating procedures to ensure alignment with equipment specifications;
• Enhancing operator training and awareness, particularly regarding the impact of improper usage on equipment reliability;
• Optimizing environmental and operational conditions, such as load levels, lubrication practices, temperature control, and vibration mitigation.
Result:
By stabilizing and improving operating conditions, organizations achieve higher MTBF, a reduction in unexpected failures, and improved operational safety. In addition to reliability gains, such improvements often strengthen collaboration between operations and maintenance functions, fostering a more integrated and proactive asset management culture.
4.6 Simplified PM and PdM (Minimalistic Preventive Maintenance)
Increasing MTBF does not necessarily require the implementation of a complex preventive maintenance (PM) program or investment in an advanced and costly CMMS. In many industrial contexts—particularly in organizations at an early stage of maintenance maturity—substantial improvements can be achieved through a simplified and pragmatic preventive maintenance approach.
Even a basic PM framework can generate meaningful results. Examples include:
• A brief daily inspection checklist (e.g., a 5 minute visual and functional check);
• Weekly condition inspections;
• Proper and timely lubrication practices;
• Monitoring temperature, vibration, or abnormal noise using basic handheld instruments.
These measures require minimal financial investment and limited organizational restructuring, yet they directly address common and preventable causes of failure.
Result:
Empirical experience across various industries suggests that the consistent application of such simple preventive and basic predictive practices can increase MTBF by approximately 30% to 70%, depending on the initial condition of the equipment and the prior level of maintenance discipline.
Beyond numerical improvement, these actions also foster routine condition awareness, early fault detection, and a gradual shift from reactive to proactive maintenance behavior.
4.7 Training, Skills, and Team Coordination (Indirect Impact on MTTR)
Although the primary objective of the improvement initiative is to increase MTBF, several supporting organizational and human factors play a critical complementary role. Key contributors include:
• Training of maintenance technicians, ensuring they possess up to date technical skills and diagnostic capabilities;
• Training of equipment operators, particularly regarding correct usage, early fault recognition, and adherence to standard procedures;
• Systematic documentation of maintenance experiences and lessons learned, providing a structured basis for continuous improvement;
• Effective coordination between production and maintenance teams, enabling faster response, shared situational awareness, and better prioritization of interventions.
Collectively, these factors ensure that when a failure does occur:
• The underlying problem is diagnosed more quickly and accurately;
• Repairs are executed with fewer errors and rework;
• Maintenance tasks are performed more efficiently, reducing delays and variability.
Unintended but Important Result:
Although these improvements are not directly aimed at MTTR, they consistently lead to reductions in MTTR and, consequently, to increased equipment availability.
Conclusion
Focusing on the improvement of the MTBF indicator not only reduces the frequency of equipment failures but also triggers a sequence of reinforcing improvements across the maintenance system. These enhancements emerge with minimal investment and are primarily driven by the systematic identification and elimination of recurring failures.
The resulting improvements include the standardization of repair procedures, better spare parts and supplier management, enhanced workforce skills, more stable operating conditions, and the implementation of simple yet effective preventive maintenance practices. Collectively, these changes increase MTBF while simultaneously reducing MTTR, thus improving overall equipment availability.
This practical and accessible approach provides an effective starting point for organizations seeking to elevate the performance of their maintenance systems without relying on complex administrative frameworks or expensive software solutions. It enables the establishment of a reliability oriented culture and lays a solid foundation for more advanced maintenance strategies in the future.
Analytical Conclusion
In many industrial organizations that are in the early stages of implementing a structured maintenance management system, the dispersion of performance indicators and the multiplicity of operational requirements can hinder the establishment of a sustainable improvement path. The analytical findings of this study indicate that MTBF, due to its direct relationship with failure rate, equipment reliability, and availability, can serve as a strategic lever for guiding corrective actions.
From a mathematical perspective, an increase in MTBF reduces the failure rate:
\[ \lambda = \frac{1}{MTBF} \]
and consequently increases the reliability function:
\[ R(t) = e^{-\frac{t}{MTBF}} \]
A higher MTBF results in a slower decay of the reliability curve over time, reflecting a reduced probability of failure within a given operating horizon. Additionally, MTBF has a direct and quantifiable impact on availability, expressed by:
\[ A = \frac{MTBF}{MTBF + MTTR} \]
Therefore, any increase in MTBF—whether or not MTTR is improved—results in a corresponding improvement in equipment availability.
From an operational standpoint, a strategic focus on increasing MTBF naturally drives the organization to introduce a series of structural improvements, including the standardization of repair procedures, optimization of spare parts management, systematic workforce training, and stabilization of operating conditions. These improvements emerge as an inherent consequence of efforts aimed at reducing recurring failures.
Thus, MTBF functions not only as a technical indicator but also as a managerial focal point that simplifies and streamlines the process of establishing a maintenance management system. By centering improvement efforts on MTBF, organizations—especially those with limited resources or low maintenance maturity—can create a clear, actionable, and sustainable pathway toward enhanced reliability and operational performance.
6. Limitations and Suggestions for Future Research
Research Limitations
Despite efforts to develop a conceptual framework explaining how focusing on a single key indicator can guide improvements in maintenance system performance, this study is subject to several limitations. The most notable limitation is the absence of field implementation and practical validation of the proposed framework in an actual industrial setting. Limited access to operational data and the need for formal collaboration with industrial organizations made large scale empirical testing infeasible at this stage.
Given that the performance of maintenance systems is heavily influenced by contextual factors—such as operating conditions, organizational structure, maintenance maturity level, and organizational culture—the practical validation of the framework across diverse industrial environments is essential. Such empirical examination would provide a more accurate understanding of the framework’s effectiveness and its adaptability to varying operational contexts.
Suggestions for Future Research
Future studies are encouraged to conduct pilot implementations of the proposed framework in collaboration with industrial partners. These pilot projects would allow researchers to:
• Evaluate the model’s effectiveness under real operational conditions;
• Identify practical challenges and contextual constraints;
• Refine and optimize the framework based on empirical evidence;
• Assess the model’s applicability across different industries and levels of maintenance maturity.
Longitudinal studies examining the sustained impact of MTBF focused improvement initiatives—particularly on MTTR, availability, maintenance costs, and organizational learning—could also yield valuable insights. Such research would help further solidify the proposed framework as a practical and adaptable tool for guiding maintenance improvement efforts.
References
Aji, J. O., & Uchendu, I. (2025). Essential and new maintenance KPIs explained. International Journal of Engineering and Management Engineering, 12(6), 1–15.
Aji, J. O., & Uchendu, I. (2025). Improving facility operations: A quantitative evaluation of MTBF, MTTR, and SLA targets. European Journal of Innovative Studies and Sustainability, 1(3), 247–261. https://doi.org/10.59324/ejiss.2025.1(3).20
Saihi, A., Ben-Daya, M., & As’ad, R. (2022). An investigation of sustainable maintenance performance indicators: Identification, expert validation and portfolio of future research. IEEE Access, 10, 124259. https://doi.org/10.1109/ACCESS.2022.3224450